
第15期 Python实现Pubmed论文信息批量抓取
2024年11月2日大约 2 分钟
第15期 Python实现Pubmed论文信息批量抓取
本期介绍一个放入pubmed的当前网址,就循环翻页抓取论文的题目,摘要,作者,doi分区等各种信息的python脚本
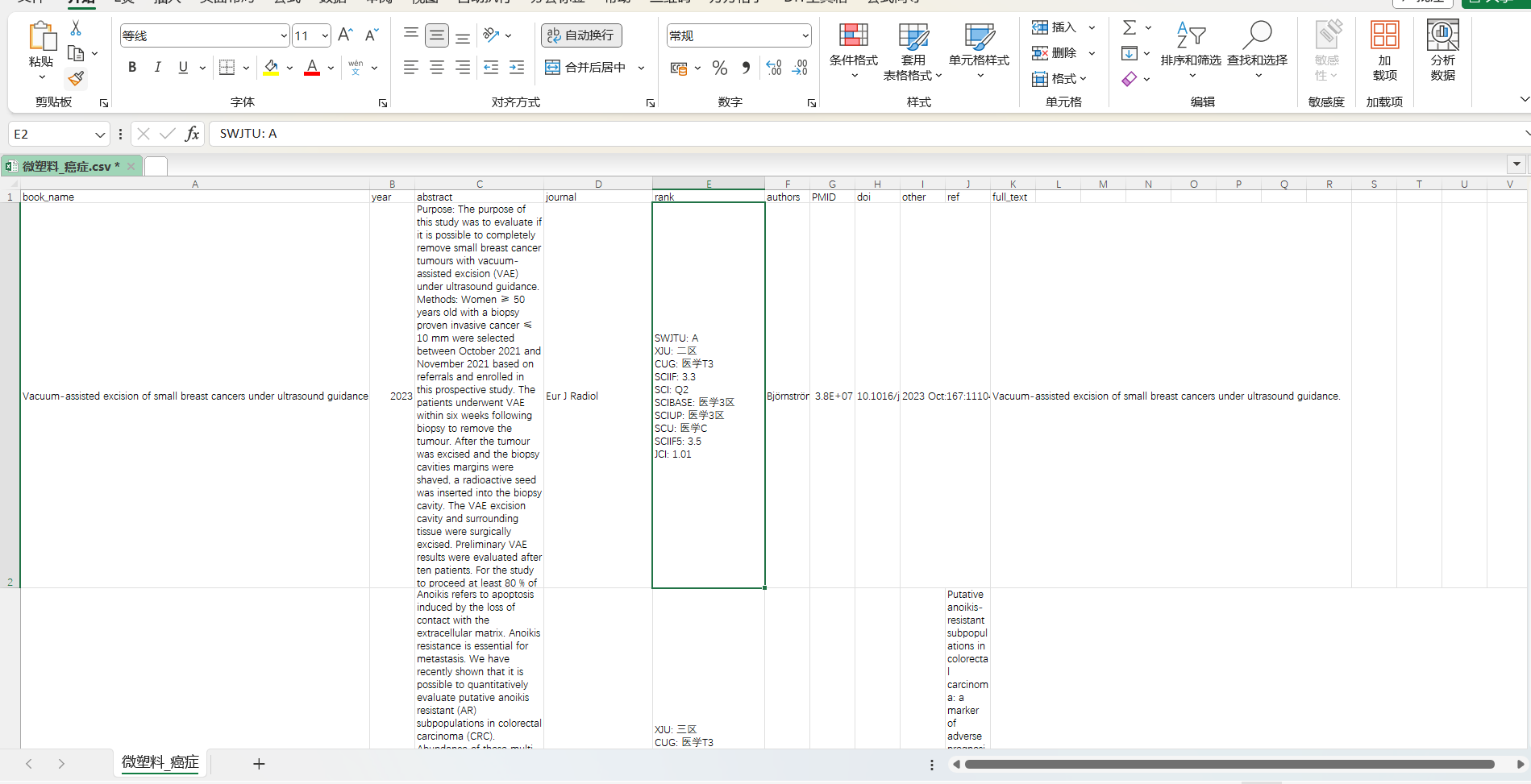
1 结果展示
抓取界面

数据界面
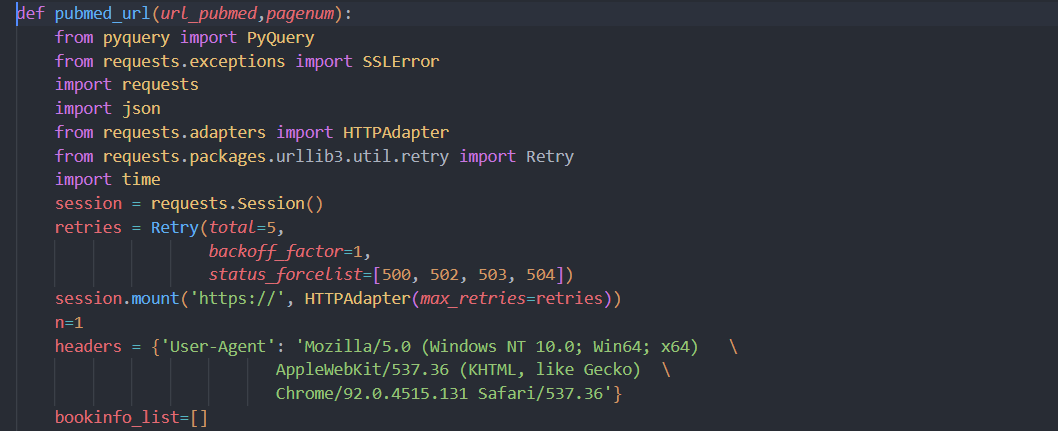
2 总代码
3 代码剖析
前期准备
- python环境
- 需要有easyscholar密钥抓取论文的分区评级和影响因子,申请方式见第8期推文
导入包
导入网页解析包pyquery(bs也可以,没有做)
导入request请求模块
设置retries,用于提高爬虫稳定性
设置请求headers
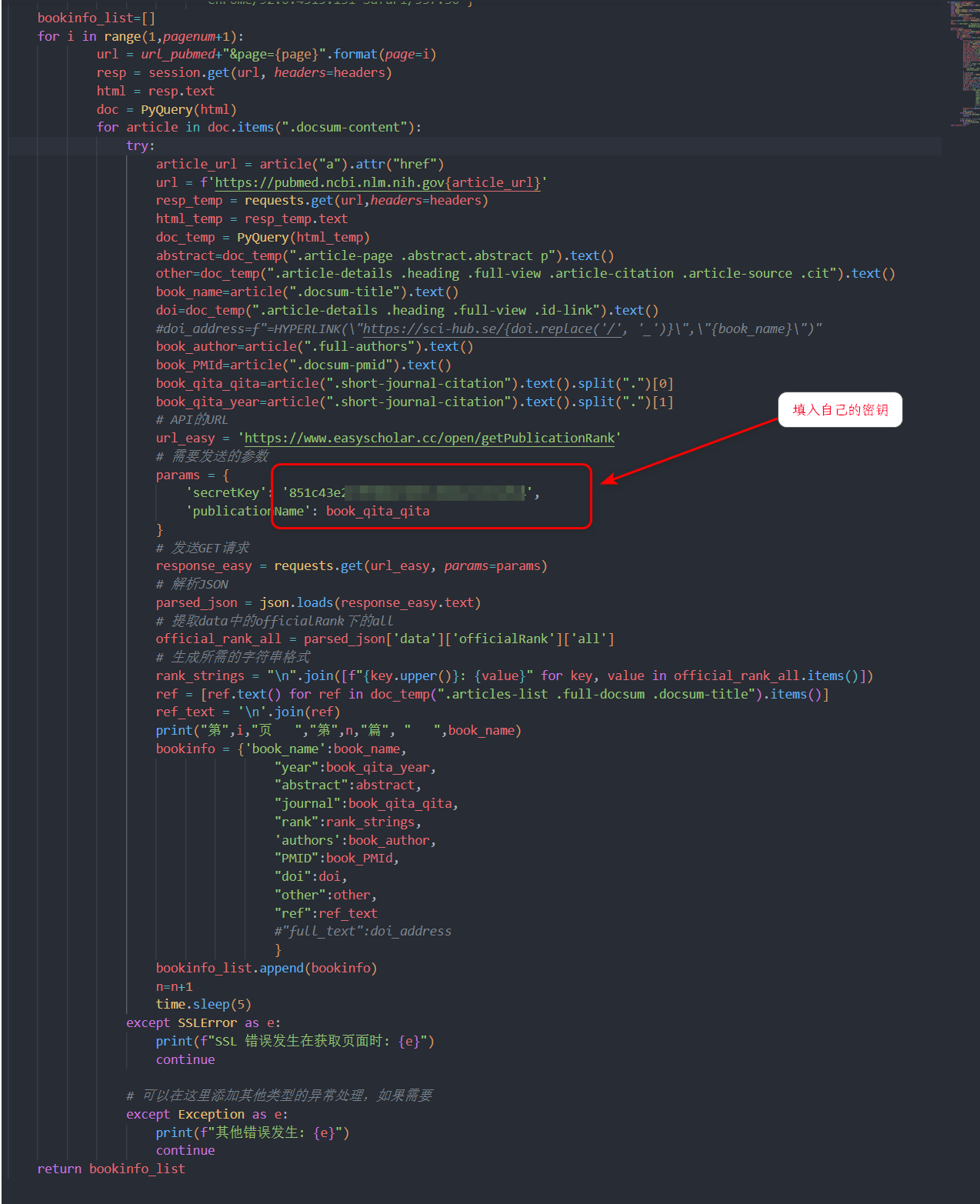
循环主体
- 循环因子是面数
- 在每一面先通过request申请到网页内容
- 实用pyquery包解析,方便元素的提取
- 查看网页的元素信息。发现论文的列表可以通过css选择器(.article-content)获取
- 遍历每一个论文,抓取题目等表信息
- 根据每个论文的href属性,抓取该论文的主页网址
- 访问主页网址,并根据css选择器(需自行学习),获取摘要和DOI号等信息
- 抓取到DOI后使用json模块,访问easyschlar官网,获取论文的分区和影响因子
- 将论文信息保存到字典,后缀到列表中
- 使用except,抓取错误信息,保证循环顺利进行
论文保存,使用pandas模块进行数据导出

注意事项
- 输入为:两个参数 par1 当前页面的网址(为了避免太多参数)。 par2:需要获取的页数
- 进入pubmed,进行检索,复制上方窗口网址(注意网址不要带&page=0,有的话删掉再放进函数)
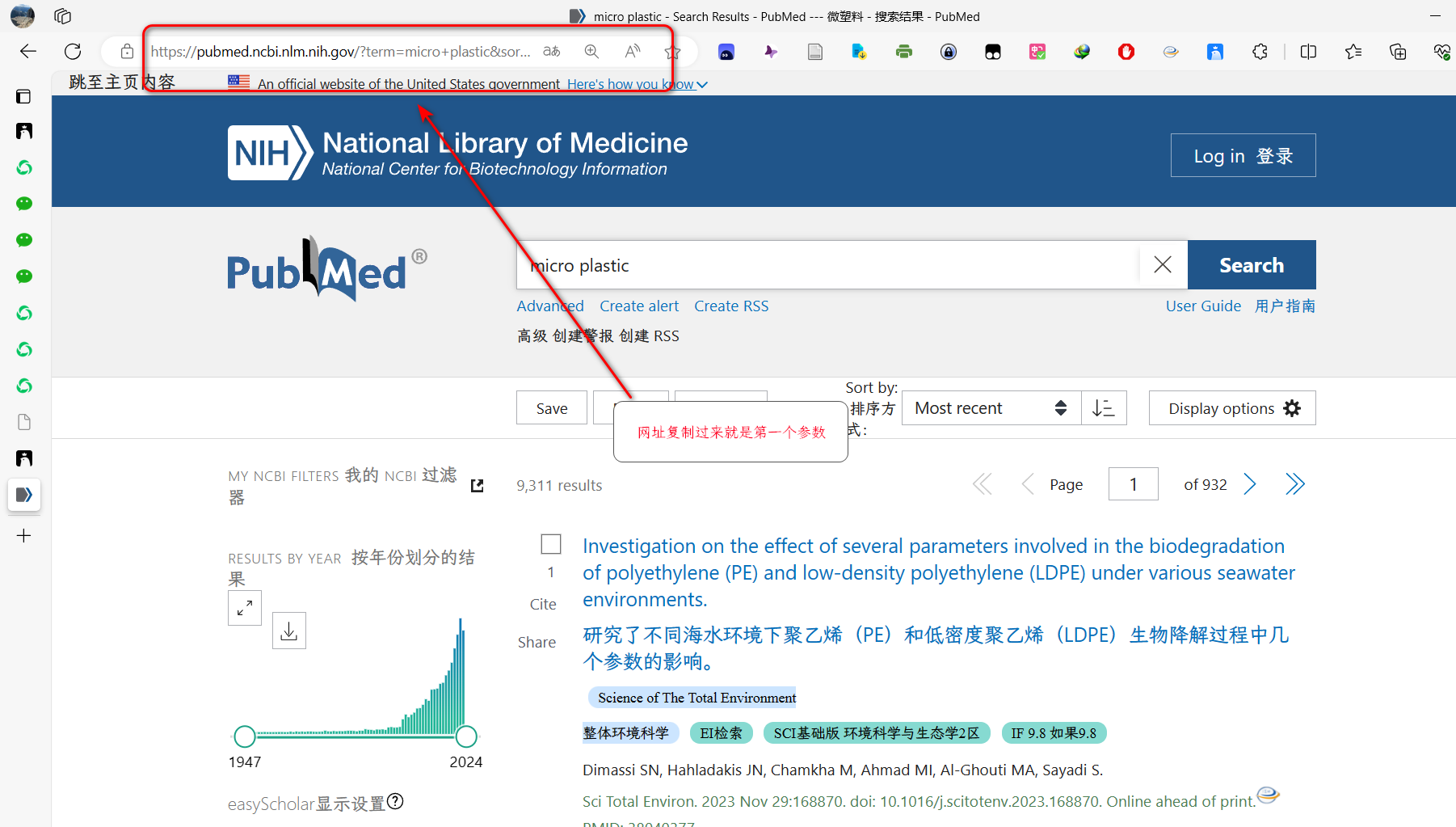
- 可进行操作的点
- 在框架下,根据CSS选择器可自定义抓取哪些元素并排序