
第13期 python实现知网论文信息获取
2024年11月2日大约 3 分钟
第13期
本期以实用为导向,介绍如何使用selenium模块实现知网条目抓取
个人学习用
2 实现效果
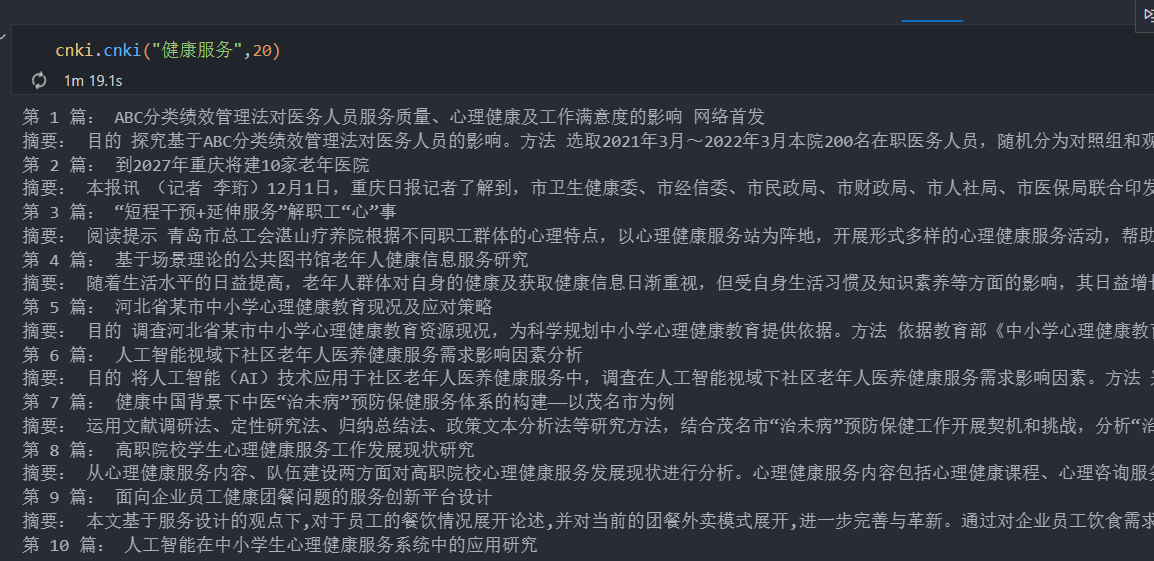
根据主题词和设定论文数即可实现知网论文信息批量获取
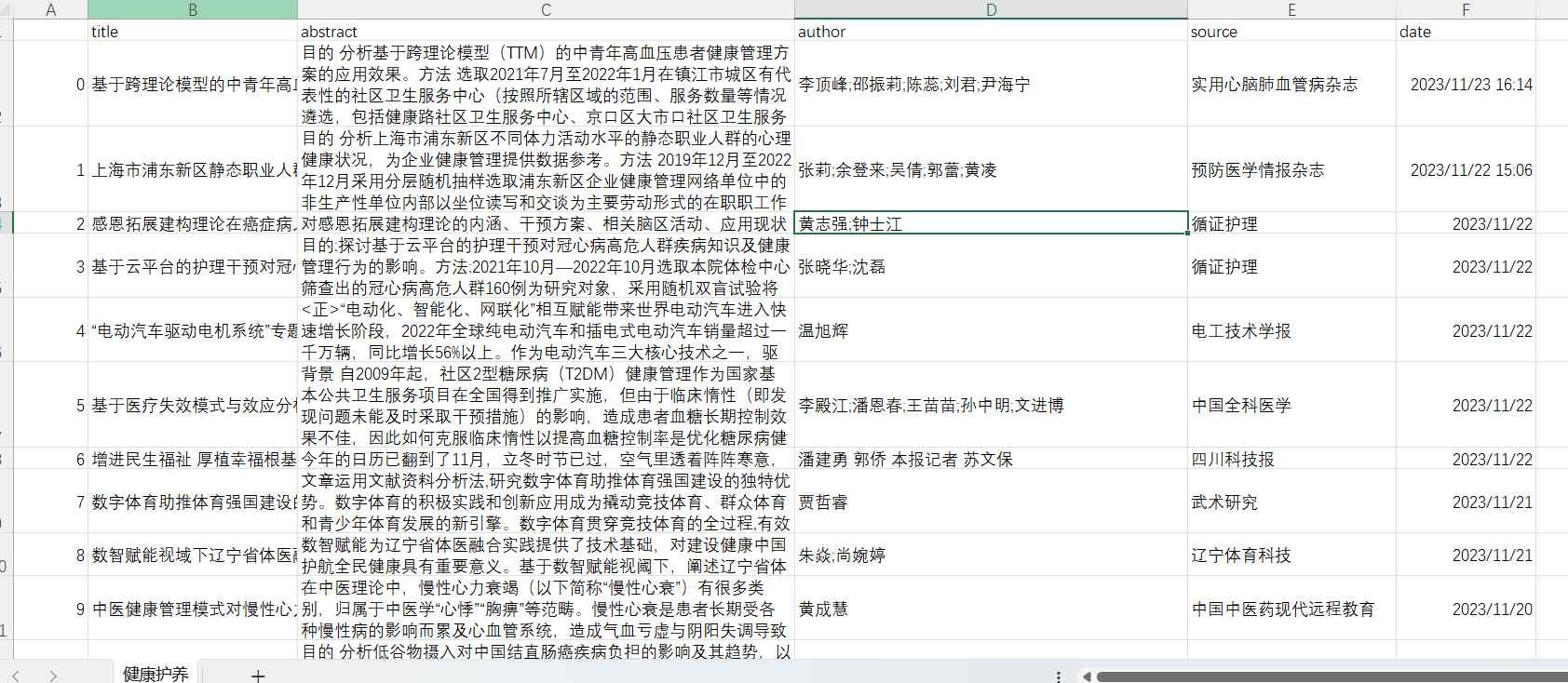
3 Python总代码
def cnki(theme, paper_need,file_names):
from selenium import webdriver
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
desired_capabilities = DesiredCapabilities.EDGE
desired_capabilities["pageLoadStrategy"] = "none"
# 设置 Edge 驱动器的环境
options = webdriver.EdgeOptions()
# 设置 Edge 不加载图片,提高速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
driver = webdriver.Edge(options=options)
driver.get("https://kns.cnki.net/kns8/AdvSearch")
time.sleep(3)
# 传入关键字
WebDriverWait(driver, 100).until(
EC.presence_of_element_located((By.XPATH, '/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[1]/div[2]/input'))).send_keys(theme)
time.sleep(3)
# 点击搜索
WebDriverWait(driver, 100).until(
EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input"))).click()
time.sleep(3)
main_window_handle = driver.current_window_handle
article_list=[]
count = 1
while count <= paper_need:
title_list = WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.CLASS_NAME, "fz14")))
for i in range(len(title_list)):
try:
if count % 20 != 0:
term = count % 20 # 本页的第几个条目
else:
term = 20
title_xpath = f"/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[2]"
print("第",count,"篇:",WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, title_xpath))).text)
author_xpath = f"/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[3]"
source_xpath = f"/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[4]"
date_xpath =f"/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[5]"
##database_xpath = f"/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[6]/a"
title=WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, title_xpath))).text
author=WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, author_xpath))).text
source=WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, source_xpath))).text
date=WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, date_xpath))).text
title_list[i].click()
n = driver.window_handles
# driver切换至最新打开的页面
driver.switch_to.window(n[-1])
time.sleep(3)
# 获取并打印摘要文本
print("摘要",WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "abstract-text"))).text)
abstract = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "abstract-text"))).text
article_dic = {"title":title,
"abstract":abstract,
"author":author,
"source":source,
"date":date}
article_list.append(article_dic)
# 关闭当前窗口并切换回主窗口
driver.close()
driver.switch_to.window(main_window_handle)
if count == paper_need:
break
except:
print(f" 第{count} 条爬取失败\n")
continue
finally:
# 计数,判断篇数是否超出限制
count += 1
# 额外等待时间,确保页面加载完成
time.sleep(3)
if count-1 >= paper_need:
break
else:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a"))).click()
time.sleep(5)
import csv
# 使用utf-8-sig编码
with open(file_names, 'w', newline='', encoding='utf-8-sig') as file:
writer = csv.DictWriter(file, fieldnames=article_list[0].keys())
writer.writeheader()
for bookinfo in article_list:
writer.writerow(bookinfo)4 代码剖析
预先准备
下载浏览器的webdrive,以便后续代码调用
网址(https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/)
导入模块
- 导入模块
- 选择部分默认设置
- 加载webdrive

进入搜索界面并输入搜索主题内容
- 模拟打开知网高级搜索界面
- 查找网页元素。在对应input框内插入搜索词(可自定义)
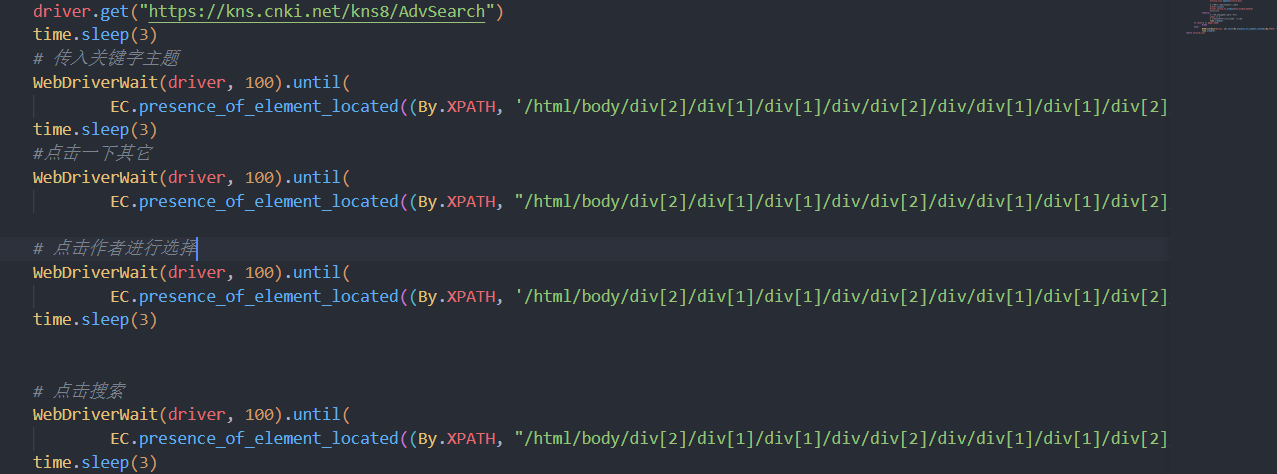
模拟点击进行搜索

模拟鼠标操作,进行循环
- 循环主体代码
- 获取当前条目的信息,包括作者,期刊,标题及日期
- 模拟点击进入条目主页,获取摘要信息。
- 保存信息到字典文件,以便后续保存
- 切换回主搜索界面,进行循环
- 由于部分网页加载不完全,可能会无法抓取摘要。添加try-except。失败时刷新网页,保证循环正常进行
- 最终返回article_list列表



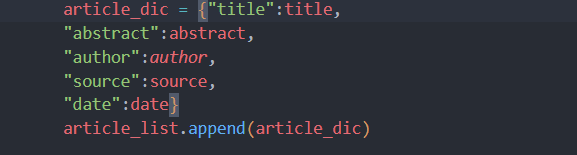

保存结果
实用pandas模块,保存至csv文件里

5 注意
- 代码基于selenium,稳定性好,不风控,但速度慢
- 代码中关于信息填入,以及抓取的条目,可以进行很好的自定义。
- 具体如何实现,可参考selenium如何抓取网页元素(XPATH选择已经很好用)
- 仅供文献大量阅读时用。