
第27期 python操作(一),pandas数据预处理函数汇总及实例展示
2024年11月2日大约 10 分钟
第27期
本期主要介绍python中pandas模块实现数据清洗的各过程及函数方法实现
目录
[TOC]
Pandas介绍
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas功能实现
模块的安装
pip install pandas数据处理基础知识
- 概念
- 针对对象(python的所有变量(不止变量)都是对象,例:Panda里的DataFram和Series都是对象,有不同的方法
- 函数:直接使用,对象可作为函数的参数使用。例:pd.read_csv("data.csv")。pd是模块,pd.read_csv是pd里的一个函数
- 方法:可以理解为包含在特定对象里的方法,不同的对象包含不同的方法。例:df.to_csv("data.csv",index=False)。df是对象,.to_csv("data.csv",index=False)是方法,可以实现将对象保存到路径的作用
- 属性:对象的内在属性,使用.atri的方式调用。例:df.shape 。其中df是对象,shape是对象的属性
数据的读取和写入
从CSV读取数据
import pandas as pd #模块缩写,后边使用方便
data=pd.read_csv("data.csv") #调用read_csv函数读取文件,并储存到data变量- 注意事项
- 在读取 CSV 文件时,需要确保文件存在且可读。
- CSV 文件中的数据可以是以逗号分隔的,也可以使用其他分隔符如制表符等。在读取时,可以根据实际情况设置分隔符参数 sep 来解析数据。
- pandas 会将 CSV 文件中的第一行作为表头(Header),如果 CSV 文件没有表头,可以通过设置 header 参数来指定
从excel文件中读取数据
import pandas as pd #模块缩写,后边使用方便
data=pd.read_excel("data.xlsx",sheet_name="sheet1") #调用read_excel函数读取文件,并储存到data变量- 注意事项
- sheet_name:修改读取的工作表名
数据保存至CSV
import pandas as pd
data = {'Name': ['Tom', 'Nick', 'John', 'Cindy'],
'Age': [20, 25, 30, 35],
'Gender': ['M', 'M', 'M', 'F']}
# 数据转换为dataframe
df=pd.DataFrame(data)
df.to_csv("data.csv",index=False)#调用DataFrame类的方法to_csv保存至指定路径- 注意事项
- 上述代码中,首先创建了一个示例数据,包含了姓名、年龄和性别等信息。然后使用 pandas 库将数据转换为 DataFrame 格式。最后使用 DataFrame 的 to_csv()方法将数据保存到名为 data.csv 的 CSV 文件中。
- index=False 参数表示不保存索引值到 CSV 文件中。
将数据保存到 Excel 文件中
import pandas as pd
data = {'Name': ['Tom', 'Nick', 'John', 'Cindy'],
'Age': [20, 25, 30, 35],
'Gender': ['M', 'M', 'M', 'F']}
# 数据转换为dataframe
df=pd.DataFrame(data)
df.to_excel("data.xlsx",index=False)#调用DataFrame类的方法to_csv保存至指定路径- 注意事项
- 可以根据实际需求进行修改和扩展。
- 在保存数据时,可以指定保存的文件名和路径,只需修改 to_excel() 方法 中的参数。
- 在保存数据时,如果不希望保存索引列,则可以将 index 参数设置为 False。
数据结构与信息
创建对象
# 创建series对象
pd.Series([1, 3, 5, np.nan, 6, 8])#包含整数
pd.Series(['a', 'b', 'c'], index=[1, 2, 3])#包含字符串
# 可以通过指定索引来自定义 Series 对象的索引,索引可以是任意类型的数 据,如整数、字符串、日期等
#创建一个DataFrame对象
# 创建一个字典,键为列名,值为列表形式的数据
data = {'Name': ['Tom', 'Jerry', 'Spike', 'Tyke'],
'Age': [5, 6, 4, 2],
'Gender': ['Male', 'Male', 'Male', 'Female']}
# 使用字典创建一个DataFrame 对象
df = pd.DataFrame(data)- 注意事项
- series和DataFrame维度上是一维和多维
- 定义上和结构接近于R的vecter和dataframe
查看对象前几行
# 查看 DataFrame 的前两行
print(df.head(2))
# 查看DataFrame 的后几行,默认为5 行
last_rows = df.tail(3) # 查看后3 行
print(last_rows)- 注意事项
- 当我们想要查看 DataFrame 的前几行时,可以使用 head() 方法,并指定需 要显示的行数作为参数。
- 默认情况下,head() 方法会显示前 5 行数据。
- DataFrame 的行索引是从 0 开始的。
- 在实际使用时,可以根据数据的大小来决定需要显示的行数,以便更好地查看数据。
查看对象DataFrame的变量名(列名)
print(df.columns)#调用df的column属性并打印到屏幕返回的结果是一个index对象
查看对象DataFrame的形状(行数列数)
print(df.shape)#调用df的shape属性并打印到屏幕查看对象(DataFrame)的统计摘要信息
print(df.describe())#调用df的describe方法并打印到屏幕查看对象DataFrame的数据类型
# 查看 DataFrame 的数据类型
print(df.dtypes) #调用df的dtypes属性并打印到屏幕查看对象DataFrame中的唯一值
# 查看DataFrame中的唯一值
unique_values = df['A'].unique()
# 首选使用[""]选中列,后使用uniqe()方法挑选为唯一值
print("唯一值:", unique_values)- 注意事项
- unique()函数只能用于 Series 类型的数据,如果想查看整个 DataFrame中的唯一值,需要对每一列使用unique()方法。
- unique()函数返回的结果是一个数组,可以通过索引和切片等方式进行进一步操作。
- 在数据分析和处理中,查看DataFrame中的唯一值可以帮助我们了解数据的 特点和分布情况。
查看对象DataFrame中的缺失值
# 创建一个包含缺失值的DataFrame
data = {'Name': ['Tom', 'Nick', 'John', 'Amy', 'Emily'],
'Age': [20, 25, None, 30, 35],
'Country': ['USA', None, 'Canada', 'UK', 'Australia']}
df = pd.DataFrame(data) # 查看DataFrame 中的缺失值(NaN)
print(df.isnull())- 注意事项
- 使用 isnull()方法来查看 DataFrame 中的缺失值情况。
- 该函数会返回一个与 df 具有相同维度的 DataFrame,其中的每个元素为布尔值,表示该位置是否为缺失值。
查看对象DataFrame中的重复值
# 创建一个DataFrame
data = {'Name': ['Tom', 'Tom', 'Jerry', 'Jerry', 'Spike'],
'Age': [25, 25, 30, 30, 5],
'City': ['New York', 'New York',
'Los Angeles', 'Los Angeles', ' Texas']}
df = pd.DataFrame(data) # 查看DataFrame 中的重复值
duplicates = df.duplicated()
print(duplicates)- 注意事项
- 使用.duplicated方法,返回一个布尔值的series,标记重复情况
- 如果需要查找并保留所有重复数据,可以使用参数 keep='first'或者 keep=False。
- 如果需要查找并保留最后一次出现的重复数据,可以使用参数 keep='last'。
- 如果需要查找并标记所有重复数据,可以使用参数 keep='False'。
数据的选择与过滤
选中列
# 选择一列
df["name"] #选择对象的name变量列
# 选中多列
df[["name1","name2"]] #通过列标签选中对象的多列
df.iloc[:,[0,2]] #通过索引值选择多列- 注意事项
- 通过列标签选择多列时,使用双重方括号[['col1', 'col3']]来指定多个列标签。
- 通过索引值选择多列时,在iloc方法中使用两个方括号,第一个方括号指定选取的行范围,第二个方括号使用列表方式指定多个列的索引值。
选中行
# 选中一行
row1 = df.loc[2] # 通过索引选择某一行 选择索引为2的行
row2 = df.loc[df['Age'] > 25] # 通过条件选择一行,只选择Age 大于25 的行
# 选中多行
df_slice = df[1:4] #使用切片操作符选择连续的行范围
filtered_df = df[df['Age'] > 25] #使用条件选择连续的行范围
# 使用逻辑运算符进行多条件选择
filtered_data = df[(df['Age'] > 30) & (df['Salary'] > 6000)]# 选择年龄大于30 且薪水高于6000的数据行
# 过滤DataFrame中的缺失值
df_dropna = df.dropna()# 删除包含缺失值的行
df_dropna_col = df.dropna(axis=1)# 删除包含缺失值的列
df_fillna = df.fillna(0)# 填充缺失值- 注意事项
- 注意事项
- 删除缺失值会改变 DataFrame 的大小,需要谨慎使用。
- 在填充缺失值时,可以根据需求选择使用不同的填充方式,如使用 0、均值、 众数等。
- 对于大规模的数据集,处理缺失值可能需要较长的时间,需要注意性能问题。
- 注意事项
数据编辑与处理
添加及删除列
# 添加列
data = {'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [23, 31, 27, 35],
'城市': ['北京', '上海', '广州', '深圳']}
df = pd.DataFrame(data)
df['性别'] = ['男', '男', '女', '男'] # 添加新列'性别'到DataFrame
#删除列
df = df.drop('age', axis=1)# 删除DataFrame 中的某一列使用列标签来引用新列并赋值给它,以添加新列到 DataFrame。
在删除 DataFrame 中的某一列时,我们可以使用 drop方法,指定要删除的列的标签(这里是'age')以及 axis=1 表示删除列。
修改列名
# 使用 rename() 函数修改列名
df.rename(columns={'Name': '姓名',
'Age': '年龄',
'City': '城市'},
inplace=True)- 注意事项
- rename() 函数可以修改 DataFrame 的列名。要指定要修改的列索引和新的列名,可以使用一个字典作为参数。
- 为了在原 DataFrame 上直接修改列名,需要将 inplace 参数设置为 True。如果没有设置inplace 参数或将其设置为False,rename() 函数将返回一个修改后的新DataFrame,并保留原 DataFrame的列名。
修改某列数据
# 修改第二行的数据
df.loc[1] = ['Mike', 35, 'Berlin']- 注意事项
- 通过df.loc[row_index] 可以访问和修改 DataFrame 中特定行的数据,其中row_index 为要修改的行的索引。
- 使用=号赋值给 df.loc[row_index] 可以修改该行的数据。
数据排序
df_sorted = df.sort_values('年龄')# 按照年龄列进行升序排序- 注意事项
- 在使用 sort_values()方法进行排序时,需要传入要排序的列名作为参数。
- 默认情况下,sort_values()函数按照升序排序,如果需要降序排序,可以设置参数ascending=False。
- 如果需要在多列的基础上进行排序,可以传入一个列名列表作为参数,例如 sort_values(['列 1', '列 2'])。
- 如果要对 DataFrame 的索引进行排序,可以使用 sort_index()函数。
对 DataFrame 进行列之间的计算
# 创建一个包含两个列的DataFrame
data = {'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10]}
df = pd.DataFrame(data)
# 对两列进行计算
df['C'] = df['A'] + df['B']
df['D'] = df['A'] - df['B']DataFrame 进行重塑与转置
# 创建示例
DataFrame data = {'国家': ['中国', '美国', '日本'],
'人口': [1400, 330, 130],
'GDP': [149.2, 21.4, 5.1]}
df = pd.DataFrame(data)
# 展示原始 DataFrame
print("原始 DataFrame:")
print(df)
# 使用 stack 方法进行重塑
df_stacked = df.stack()
# 展示重塑后的
DataFrame print("\n 重塑后的 DataFrame:")
print(df_stacked)
# 使用 transpose方法进行转置
df_transposed = df.transpose()
print("\n 转置后的 DataFrame:")
print(df_transposed)
- 注意事项
- 功能接近于R语言的pivot系列函数
- 使用stack方法进行重塑时,结果会变成一个 Series 对象,可以通过 unstack 方法将其恢复成原始的 DataFrame。
- 使用transpose方法进行转置时,行和列的顺序会发生改变,所以需要根据实际需求进行适当的调整。
DataFrame进行分组与聚合操作
# 对DataFrame 进行分组和聚合操作
grouped = df.groupby('Name') # 根据Name 列进行分组
agg_result = grouped['Age', 'Salary'].mean()
# 对分组后的Age 和Salary 列计算均值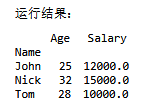
- 注意事项
- 在分组操作中,可以选择一列或多列作为分组依据。
- 对分组后的数据可以进行各种聚合操作,如求均值、求和、求最大值等。
- 聚合操作可以对不同的列进行,通过将列名传递给grouped 对象的[ ]运算符 来进行选择。
- 在聚合操作中,可以使用多个函数,如 mean()函数用于计算均值。
- 分组和聚合操作可以帮助我们从不同的维度对数据进行统计和分析。