
第31期 R语言正则表达式语法详解及使用场景
2024年11月2日大约 8 分钟
第31期 R语言正则表达式语法详解及使用场景
本期主要介绍R语言中的正则表达式的相关用法及使用
正则表达式在日常数据处理,文本处理,文本分析,爬虫等使用极多
R语言正则语法与python存在区别。本期基于R语言的正则化进行讲解
什么是正则表达式
正则表达式的概念
正则表达式,是根据字符串规律按一定法则,简洁表达一组字符串的表达式。 正则表达式通常就是从貌似无规律的字符串中发现规律性,进而概括性地表达 它们所共有的规律或模式,以方便地操作处理它们,这是真正的化繁为简,以简驭繁的典范。
正则表达式的使用场景
- 检查文本是否含有指定的特政词
- 找出文本中匹配特征词的位置
- 从文本中提取信息
- 修改文本
- 正则表达式包括
- 只能匹配自身的普通字符(如英文字母、数字、标点等)
- 被转义了的特殊字符(称为 “元字符”),用于构造匹配规则
- 比如“我数学考了100分”。用“数学”匹配就是普通字符,用“\\d\\\d\\\d”匹配“100”,就是元字符
- 正则表达式学习建议
- 先学会最常用的三个正则表达式实例
- 遇到具体问题,查阅基本语法表,尝试构造正则表达式,调试得到结果
正则表达式的常用元字符
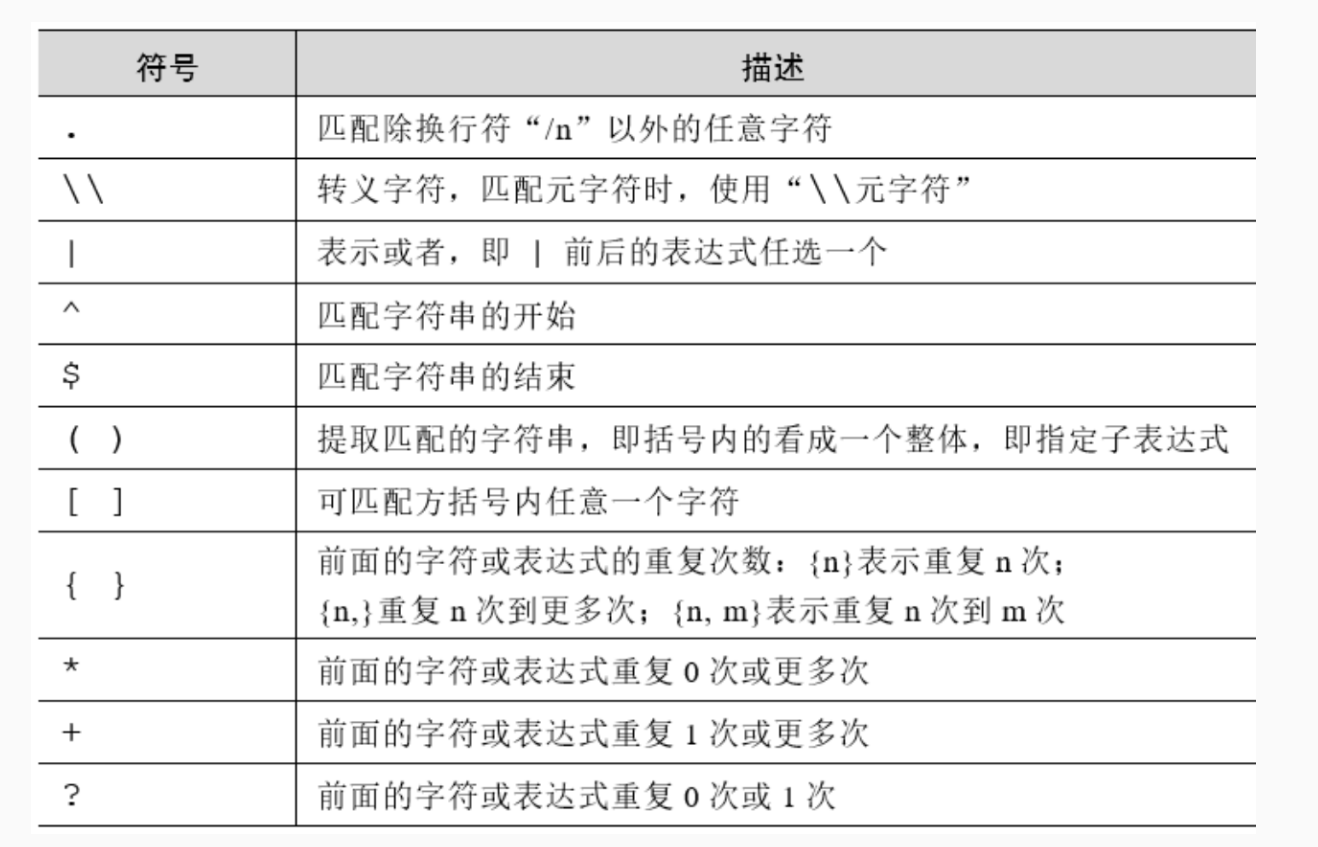
- 注意事项
- R语言的转义字符是\\。其它语言是\。也就解释R语言读取路径需要用\\连接
- 默认正则式区别大小写的,可通过添加参数来创建忽略大小写的表达式"ignore_case=FALSE"
- 在多行模式下,^ 和 $ 就表示行的开始和结束(比较常用的)
正则表达式的特殊元字符
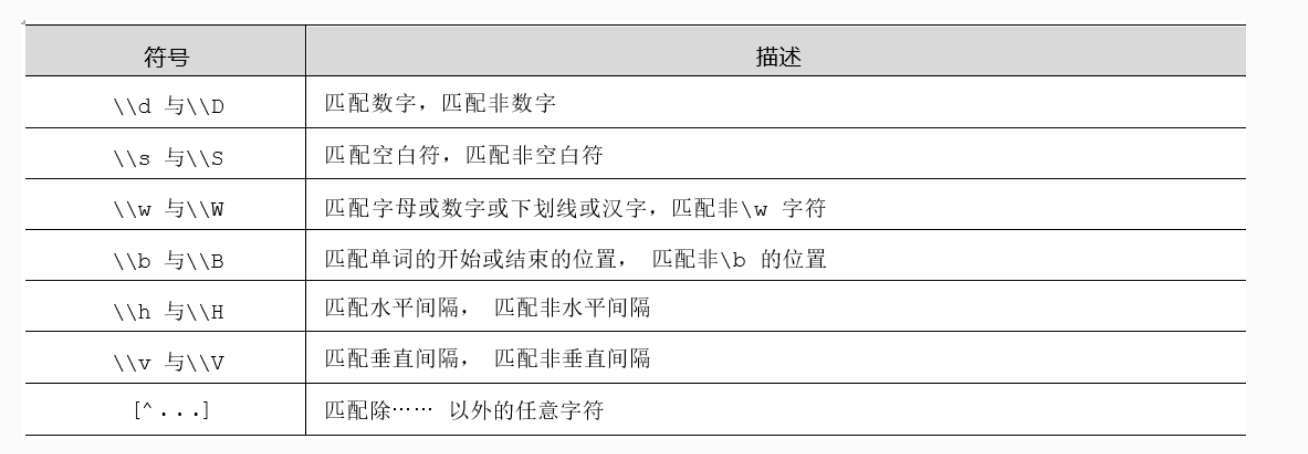
- 其它
- \S+ :匹配不包含空白符的字符串
- \d,匹配数字
- [a-zA-Z0-9]:匹配数字
- [\u4e00-\u9fa5] 匹配汉字
- [^aeiou]: 匹配除 aeiou 之外的任意字符,即匹配辅音字母
POSIX 字符类
正则表达式的实例用法
运算优先级
类似于数学运算的先后等级
在正则表达式中圆括号括起来的表达式最优先,其次是表示重复次数的操作(即 * + { });再次是连接运算(即几个字符放在一起,如 abc);最后是或者运算(|)
懒惰匹配与贪婪匹配
- 基础知识
- 正则表达式正常都是贪婪匹配,即重复直到文本中能匹配的最长范围
- 贪婪匹配:尝试匹配尽可能多的字符。例如,正则表达式
".*"会匹配给定字符串中的所有内容。 - 懒惰匹配:则相反,它尝试匹配尽可能少的字符。在R语言中,你可以通过在量词后面添加一个问号
?来实现懒惰匹配。例如,正则表达式".*?"会匹配尽可能少的字符。
实例说明
# 匹配到了最长的内容
str_extract("(1st) other (2nd)", "\\(.+\\)")
# 如果想要匹配具体的标识符内的内容
str_extract("(1st) other (2nd)", "\\(.+?\\)")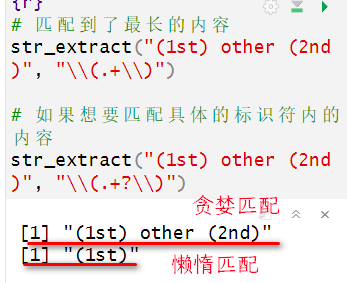
零宽匹配
零宽匹配是相对于直接匹配的高级用法。
- 适合想要匹配的内容没有规律性,但该内容位于两个有规律性的标志之间,标志也可以是开始和结束。
- 通常想要匹配的内容不包含两边的 “标志”,这就需要用零宽断言。就是一种引导语法告诉既要匹配到 “标志”,但又不包含 “标志”。
- 左边标志的引导语法是 (?<= 标志),右边标志的引导语法是 (?= 标志),而真正要匹配的内容放在它们中间。
实例说明
x = c("20 级预防医学 卓创4 班", "20 级预防医学 疾控3班")
#想要识别x中的专业名称
#观察字符串的特征,发现专业夹在"医学 "以及数字(4和3)之间,并且不包含医学和数字,所以使用零宽断言
str_extract(x, "(?<=医学 ).*?(?=[0-9])")
重复标识符处理
如一个字符串对于期望的特征定位符,有多个相同的符号来干扰。如何实现使用自己需要的位置的定位符呢
参考示例
x = paste0("D:/paper/1.65_kc_ndvi/kc/forest_kc_historical",
"_ACCESS-ESM1-5_west_1981_2014.tif")
# 想要匹配到最后的文件夹名
# 观察数据结构,在结构"kc/的右边",内部结构的组成是forest(非标识符_),加一个"__",kc(非标示符),再加一个"__",historical(非标识符)。根据要求构建正则式
str_extract(x, "(?<=kc/)([^_]+_){2}[^_]+")
- 观察数据结构,在结构"kc/的右边",内部结构的组成是forest(非标识符_),加一个"_",kc(非标示符),再加一个"_",historical(非标识符)。根据要求构建正则式为"(?<=kc/)([_]+_){2}[_]+"
- 用法说明
- str_extract(x, "(?<=kc/)([_]+_){2}[_]+"): 这一行使用
str_extract()函数从x中提取匹配正则表达式的子串。这个正则表达式"(?<=kc/)([_]+_){2}[_]+"的含义如下: (?<=kc/): 这是一个正向后视断言(positive lookbehind),它匹配"kc/"之后的内容,但不包括"kc/"本身。- ([^_]+_){2}: 这部分匹配两次不包含下划线
_的一个或多个字符序列,后面紧跟一个下划线。每个[^_]+匹配不含下划线的连续字符,_是这些字符后面的下划线。 - [^_]+: 这部分匹配紧随其后的一个不含下划线的字符序列。
- str_extract(x, "(?<=kc/)([_]+_){2}[_]+"): 这一行使用
- "+"号的用法
- 单个字符: 如果
+号跟在一个字符后面,比如a+,这意味着在目标字符串中匹配一个或多个连续的a字符。例如,在字符串"caaaat"中,a+会匹配连续的aaaa部分。 - 字符类: 当
+号用于一个字符类(character class)后面时,如[a-z]+,它会匹配一个或多个连续的在这个字符类中的字符。例如,[a-z]+会匹配字符串"hello world"中的"hello"和"world"。 - 子表达式: 如果
+号用于一个子表达式后面,比如(ab)+,它会匹配一个或多个连续的这个子表达式。例如,在字符串"ababcd"中,(ab)+会匹配开头的"abab"部分。
- 单个字符: 如果
Stringr函数实现正则化
- str_view:调试和查看正则表达式的匹配效果
- str_view(): 此函数用于调试和查看正则表达式的匹配效果。它对于理解和调整你的正则表达式非常有用,尤其是在处理复杂的字符串模式时。
str_view()函数会在RStudio的Viewer窗口中展示正则表达式在字符串中的匹配结果,使你可以直观地看到哪些部分被匹配。
- str_view(): 此函数用于调试和查看正则表达式的匹配效果。它对于理解和调整你的正则表达式非常有用,尤其是在处理复杂的字符串模式时。
- str_extract():提取正则表达式匹配到的内容
- str_extract(): 该函数用于提取匹配正则表达式的字符串内容。当你需要从文本中提取特定模式的数据时,这个函数非常有用。例如,如果你有一组字符串,如
"1978-2000"和"2011-2020-2099",并且想要提取出每个字符串中的第一个四位数字,你可以使用正则表达式"\\\\d{4}"(表示匹配四位数字),str_extract()会返回第一个匹配的结果,如"1978"和"2011"。
- str_extract(): 该函数用于提取匹配正则表达式的字符串内容。当你需要从文本中提取特定模式的数据时,这个函数非常有用。例如,如果你有一组字符串,如
- str_replace(): 替换正则表达式匹配到的内容
- str_replace(): 这个函数用于替换匹配到的字符串内容。如果你想要修改文本中的特定模式,例如,将所有的短横线
"-"替换为斜杠"/",你可以使用str_replace()。在前面的例子中,如果将"1978-2000"和"2011-2020-2099"作为输入,并用正则表达式"-"和替换字符串"/",str_replace()会将第一个匹配到的短横线替换为斜杠,返回"1978/2000"和"2011/2020-2099"。
- str_replace(): 这个函数用于替换匹配到的字符串内容。如果你想要修改文本中的特定模式,例如,将所有的短横线
- _all 版本的函数: 对于许多
stringr函数,如str_detect、str_extract等,存在一个后缀为_all的版本,比如str_detect_all、str_extract_all。这些_all版本的函数用于在字符串中查找所有匹配的模式,而不仅仅是第一个匹配。
Tidyverse下正则表达式的作用
进行变量值重编码
使用mutate函数和str系列函数
# 示例数据框
data <- data.frame(
category = c("typeA-123", "typeB-456", "typeA-789", "typeC-101")
)
data
#识别大写字母作为变量,数字作为编号
data %>% mutate(type=str_extract(category,"[[:upper:]]"),
number=str_extract(category,"\\d\\d\\d"))
进行变量名的批量修改
使用rename_with()和str系列函数进行变量名的批量修改
# 示例数据框,包含不规则的列名
data <- data.frame(
var_1 = 1:4,
Variable_2 = 5:8,
another_Var3 = 9:12
)
data
data %>%
rename_with(~str_extract(.,".*(?=_)"))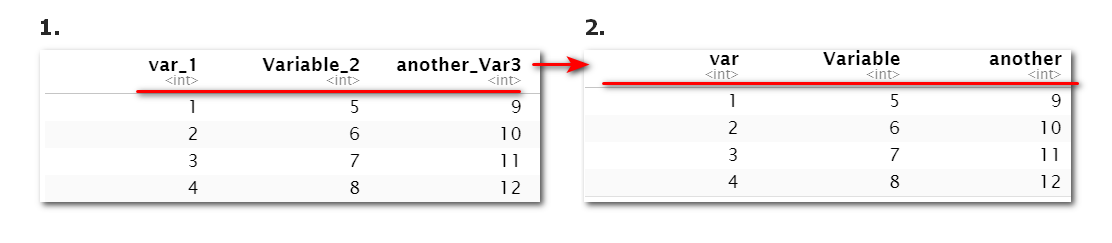
- 注意事项
~是一种简化函数定义的方法,这里它定义了一个匿名函数,其中.代表当前的列名。- 匿名函数在R语言purrr风循环中使用极多,后边会专门进行讲解
推荐书目 张敬信. R语言编程 基于tidyverse. 人民邮电出版社; 2023. Accessed October 16, 2023.