
第30期 R语言-基于tidyverse的整洁数据处理
2024年11月2日大约 7 分钟
第30期 本期主要介绍在使用R语言进行数据整洁化的常用函数及说明
目录
[TOC]
整洁数据基础说明
整洁和不整洁数据的特点
- 不整洁数据
- 首行不是变量名而是数值
- 多个变量在一列
- 变量既在行也在列
- 多种类型的观测单元在同一个单元格
- 一个观测单元格放在多个表
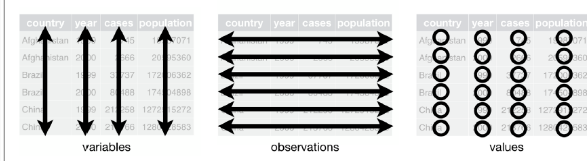
- 整洁数据的特点
- 每个变量构成一列
- 每个观测构成一行
- 每个观测的每个变量值构成一个单元格
- 整洁数据的图示
为什么要变成整洁数据
- 数据处理需要
- 大多数函数的对象是针对变量进行。数据框可以看作多个向量(每个向量是一个变量)
- 整洁数据才能保证数据的清洗准确而不波及其它
- 可视化需要
- 可视化图的ggplot包需要整洁数据才能进行可视化
- 比如研究国别与经济水平的差异。国别作为横轴(柱状图),就需要国别单独作为一个分类变量。而不能是把不同国家放在不同列里
整洁数据需要哪些操作
- 长宽表转化
- 拆分/合并列
- 方形化
典型概念之长表和宽表
- 长表之所以长是因为将变量名作为变量值,实现了长度加长
- 宽表之所以宽是由于将变量值作为变量名,变量增多,实现宽度增宽
- 典型的整洁数据应该是要减少变量名,增加变量行。即宽变长,在各个分析里更为实用
实例说明
加载包
#install.packages(tidyverse) 第一次使用要安装
library(tidyverse)新建不整洁数据
新建数据框记录同学及成绩情况
score_data <- data.frame(
observation=c("王(康)","李(卫)","张(强)"),
公卫_预防医学导论=c(50,60,70),
临床_临床概论=c(30,50,60)
)- 数据为不整洁数据
- 姓和名作为不同变量可以进行列拆分
- 需要研究人和各学科成绩之间的关系,需要把成绩作为变量放在一列。把学科情况放另一列
- 使用tidyr包进行重塑(tidyverse导入的时候就会自动加载)
进行数据重塑
数据框的宽表变长表
score_data %>% pivot_longer(
-observation,
names_to = c("学院","学科"),
names_sep="_"
)- 函数说明
score_data %>%: 这里使用了管道操作符%>%,它是dplyr包的特色之一。%>%允许你将左边的结果传递给右边的函数,使代码更易于阅读和编写。在这里,score_data这个数据框被传递给了pivot_longer()函数。pivot_longer(-observation, ...):pivot_longer()函数用于将数据从宽格式转换为长格式。在这个函数中,-observation表示所有除了observation列之外的列都将被转换。这里的负号-是排除的意思,意味着不对observation列进行操作。names_to = c("学院","学科"): 这个参数指定了新数据框中变量名的名称。在转换成长格式时,原始数据中的列名(那些除了observation以外的列)将被放入这两个新列中。这里,原始列名将被分割为两部分,分别存入学院和学科两个新列names_sep="_": 这个参数指定了在原始列名中用于分割的分隔符。在这里,_被用作分隔符。这意味着函数将查找原始列名中的下划线,并在那里将列名分割成两部分。
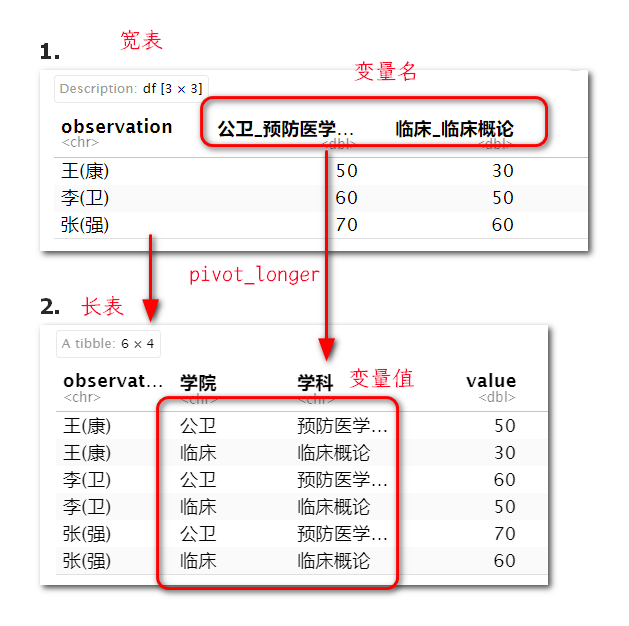
数据框转换前后比较
- 总结要点
- 宽表的特点是:表比较宽,本来该是” 值” 的,却出现在” 变量(名) “中。这就需要给它变到” 值” 中,新起个列名存为一列,即宽表变长表
- 数据框由宽变长,将变量名转换为变量值,行数增多。
- 转换出的列数由names_to的值决定,names即产生新变量名个数
整洁化函数实例
长宽表转换
宽表变长表
pivot_longer(
data,
cols,
names_to,
values_to,
values_drop_na,
...)- 参数说明
- data: 要重塑的数据框
- cols: 用选择列语法选择要变形的列
- names_to: 为存放变形列的列名中的”值”,指定新列名(变量)
- values_to: 为存放变形列中的”值”,指定新列名
- values_drop_na: 是否忽略变形列中的NA
- 注
- 若变形列的列名除了”值” 外,还包含前缀、变量名 + 分隔符、正则表达式分组捕获模式,则可以借助参数 names_prefix, names_sep, names_pattern来提取出”值”(实现长变宽及分列的作用)
参考实例
data_score <-data.frame(
name="王康",
score_2018=90,
score_2019=30,
score_2020=40
)
data_score
tidy_data_score <- data_score %>%
pivot_longer(
cols=2:4,
names_to = c("其它","时间"),
values_to = "分数",
names_sep = "_"
)
tidy_data_score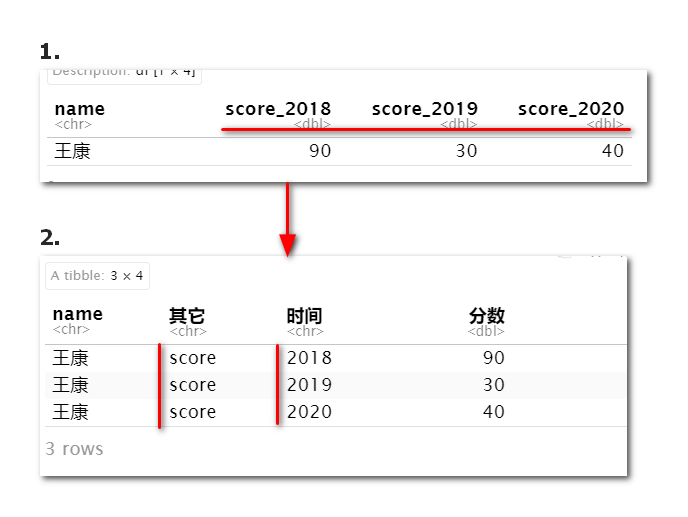
长表变宽表
长表的特点是:表比较长。有时候需要将分类变量的若干水平值,变成变量(列名)。这就是长表变宽表:
使用pivot_wider函数
pivot_wider(data,
id_cols,
names_from,
values_from,
values_fill, ...)- 参数说明
- data: 要重塑的数据框
- id_cols: 唯一识别观测的列,默认是除了 names_from 和 values_from 指定列之外的列
- names_from: 指定列名来自哪个变量列 (也就是哪列要作为变量,一般是分类变量)
- values_from: 指定列”值” 来自哪个变量列
- values_fill: 若变宽后单元格值缺失,设置用何值填充
实例说明
tidy_data_score %>%
pivot_wider(
names_from = "时间",
values_from = "分数"
)
列的拆分与合并
列的拆分
一列根据分隔符变成多列,但行数不变
使用seperate函数
separate(data,
col,
into,
sep, ...):- 参数说明
- data,数据框,在管道符传递中可忽略
- col,需要拆分的行
- sep,拆分的依据(分割符)
- into,为拆分后的行起名
实例说明
score_data <- data.frame(
observation=c("王(康)","李(卫)","张(强)"),
公卫_预防医学导论=c(50,60,70),
临床_临床概论=c(30,50,60)
)
# 使用到了正则表达式,之后会更
score_data %>%
separate(col=observation,
sep = "\\(",
into = c("姓","名"))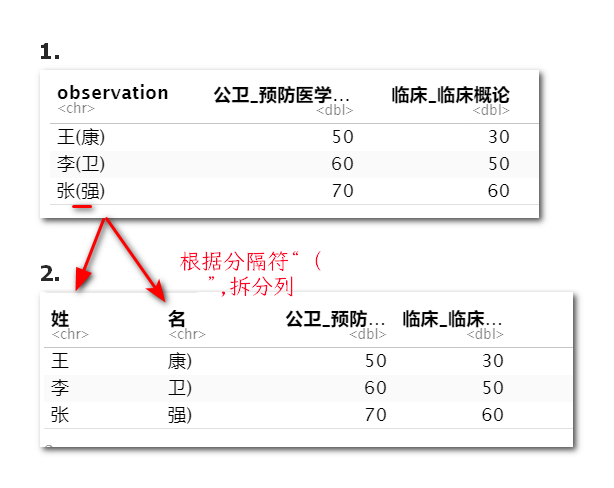
列的合并
使用unite函数
unite(data,
col,
sep, ...)- 参数说明
- seperate的逆操作
- 用分隔符sep将多列合并为一列
实例
score_data %>%
separate(col=observation,
sep = "\\(",
into = c("姓","名")) %>%
unite(
new,
姓,
名,
sep="(")- 说明
unite(new, century, year, sep = ""):unite()函数用于将多列合并成一列。在这个例子中,new是合并后新列的名称,century和year是要被合并的两列的名称。new: 合并后的新列名。century: 第一个要合并的列。year: 第二个要合并的列。sep = "": 这个参数指定合并时列之间的分隔符。在这里,sep = ""表示在合并century和year这两列时,不在它们之间添加任何分隔符。
行的拆分
使用separate_rows函数对不定长的行进行分行,堆叠放置
使用与separate接近,但是是堆叠放置,可等同于拆分行
实例
data=data.frame(
name=c("王康"),
score=c("这学期还行,下学期努力,吗?")
)
data
data_sep_rows <- data %>%
separate_rows(
score,
sep=","
)
data_sep_rows
方形化
方形化(Rectangling)是将一个深度嵌套的列表(通常来自 JSON 或 XML)驯服成一个整齐的行和列的数据集。主要通过组合使用以下函数实现
- unnest_longer():提取列表列的每个元,再按行存放(横向展开)
- unnest_wider():提取列表列的每个元,再按列存放(纵向展开)
- unnest_auto():提取列表列的每个元,猜测按行或按列存放
- hoist():类似 unnest_wider(),但只取出选择的组件,且可以 深入多个层
方形化的展开嵌套的概念较为难以理解,以下通过实例来具体说明一下
- 建立不整洁数据,观察数据特征
- data列是不同的因变量对应的数据框(不同的人检测项目不一样,数据框也不一样。但测过中性粒细胞比率的又一定测过中性粒细胞数)
- var_y列是数据框中的因变量
- 由于var_y列属于不整洁数据,要分析在各个数据框下不同检测指标的情况,需要将var_y列由嵌套的向量转换为方形的块(没有嵌套结构)

- 进行方形化
- 使用unnest_longer的效果与直接unnest一样

#方形化代码,打开嵌套结构
data <- tibble(
var_y=dependent2,
data=list_2_all,
group=names(dependent2)
) %>%
unnest_longer(var_y)注意事项
- 做好数据整洁化需要补充的知识说明
- tidyverse入门知识
- 管道符的使用
- 正则化知识(在不整齐的数据值中格外实用)
- 后续会缓慢更进